
AN AUTOPSY OF A DATA SCIENTIST

Let’s imagine someone just died, it should not be too hard given that every 2 seconds someone does die[1]. It was a data scientist, a great one. We’ll refer to this data scientist as ‘she’ for the remainder of the post. We’re going to perform an unusual autopsy on her, one that reveals how she spent her life as a data scientist. We’re going to ignore all the other stuff she did, and just focus on the data science aspect of her life. The TL;DR version is that she wanted to do the maths version of something like the below photo.
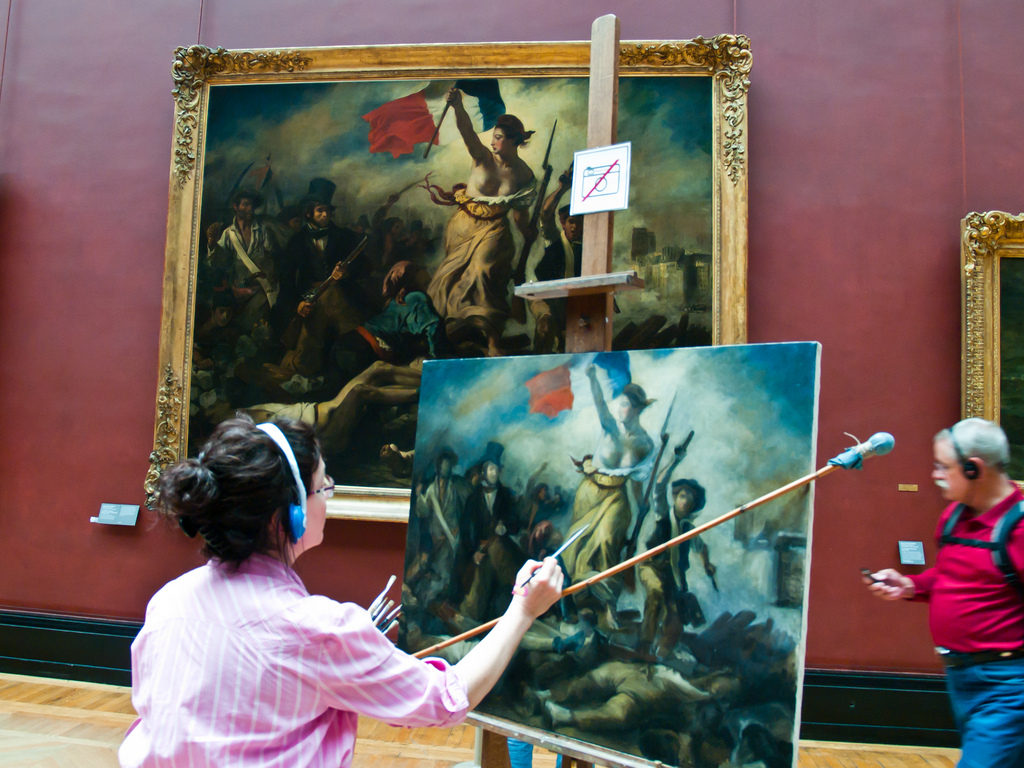
She imagined herself, at least to some extent, as someone who would be spending her time doing something creative, something unique, sort of painting a masterpiece I guess. Instead, she ended up altogether different.

It’s fine when you do it for 3x5mins, but tough when you do it 12-14 hours per day. Another appropriate image to describe how her life turned out, would have been the lady from the Anvil ad. But then again, her headaches were a different kind, one that no pill would cure or give relief to.
On the Miserliness of a Data Scientist
Don’t get me wrong, I love data science. I had more fun working in the field than I had with any other individual thing. Even though the term is relatively new, or at least in the popular context it has today, I have been one for over 20 years. The single most important thing that I learned during the two decades is that “YOU HAVE TO LEARN A LOT OF THINGS ALL THE TIME”.
Just how much do you have to learn? She spent roughly 20% of her time just learning. Indeed, on a given day she would be learning:
- three different languages (not the ones people speak)
- the syntax of multiple packages related to just one language
- statistics and maths
There is more, but those are the primary ones. When it comes to three different languages on a given day (I’ve sometimes had to be learning 5 different ones on a single day), who does it I want to ask? I’ve taxed my cognition in many imaginable and unimaginable ways, but few things come close to the load this puts on you. My personal record was over 300 pageviews on StackOverflow on one very long day. If you work 10 hours without any break, that’s one visit every 2 minutes. How about learning for example python packages. You might spend a good part of your day, sometimes the whole day going through manuals of some visualization library, a modeling library and something you use for data transformation. All approximately at the same time because you have to build some demo or something like that. Once you know the quality of the so-called documentation common libraries have, it will make you want to cry. If you are self-interested, you will cry for yourself, and if you’re compassionate, you will cry for countless others that are forced to go through the same. The parts of our brain that are associated with altruism and self-interest can’t fire at the same time, so at least you can’t cry for both. Then the worst part, learning about stats and maths. By that I mean, I can’t imagine how something so interesting and fun as learning about maths, can be made as mind-numbingly boring (and painful) as is the case with Wikipedia and other common resources regarding the topic (the stuff you find through Google).
“If I had to design a mechanism for the express purpose of destroying a child’s natural curiosity and love of pattern-making, I simply wouldn’t have the imagination to come up with the kind of senseless, soul-crushing ideas that constitute contemporary mathematics education.” – Mathematician Paul Lockhart
For anyone who’ve spent time reading Wikipedia articles on stats topics, knows this soul-crushing has not gone to waste. The tradition is alive and thriving.
On Painting Masterpieces
Regardless of this, Data Science is amazing. It is very much like playing a computer game, while yourself are part of designing it, and then getting paid for it. Instead of nagging, you get rewarded for doing it day and night. It is also kind of a superpower; you can access data on almost anything, use your hard earned skills, and predict stuff that others can’t. Unfortunately, even relatively simple projects can become a struggle if you want to do them really well and can take a really long time. And guess what, unless things go into a new direction, mediocre data science skills won’t be valued for long. Soon the ability to predict things will be completely commoditized. It’s just a matter of time, just look at things like Gnosis[2] or PredictionToken as examples. Or how companies like Baidu and Google are ramping up on their AI capabilities. Is it by coincidence that the two leading search-and-retrieval companies are also the ones that have rapidly become the leading machine intelligence companies? Now you go to Google to search stuff, but in the not-so-distant future, Google comes to you and you pay so that their AIs can tell you things. In this game, the individual data scientist will lose. Unless data science is democratized first. At the moment, the game is rigged against the data scientist.
Think about the convergence of voice technologies, deep learning, and search and retrieval. In that vision of the future, the data scientist of today is the janitor of tomorrow. Look at what happened to engineers, and what is rapidly happening to computer programmers. They spend most of their time doing mundane tasks and go from one job to another after a bigger paycheck, while their paymasters search for the next billion dollar business model. It was starkly different to be a computer scientist in the 60s. If you want to get a glimpse of just how different, see the Mother of All Demos for reference. The big difference is that whereas the early engineers and computer scientists were awe inspiring, the data scientists of today are not. They are busy chasing a paycheck or building a social media presence.
The way for a data scientist to remain relevant is to unlock creativity, human ingenuity. To make sure that you operate a level where the machine can never operate, and the way to do that is to work skillfully and effectively in a symbiotic relationship with the machine. This can be seen as a three-step progression:
1. Skill
2. Efficiency
3. Creativity
The skill aspect encompasses things like programming (at least for now), statistics, mathematics, data visualization, storytelling, etc. etc. The efficiency aspect relates to how you are able to work with a broad range of challenges with minimal cognitive cost. This includes the tools you use, your working habits, your learning process, and many other things. Both skill and efficiency are intimately connected with the idea of working symbiotically with the machine. Creativity is the end game, it is the result of mastering skill and efficiency. Just like in painting, no matter how creative you are, unless you can hold the brush and know a little bit about paints, there is very little you can do. Those who can get so far, can’t be replaced by AIs later.
From the organizational standpoint, nobody in their right mind reduces truly creative people into janitorial roles. If you’re really good at what you’re doing, and you are creative, like she was, it’s very hard to keep doing that which you are very good at. INSTEAD, you will be moved to sales and managerial roles, or worse yet, roles that involve both. She ended up spending roughly 15% of her time with business development and managerial tasks. If somebody told her this would happen, before she “signed up” to a career in data science, she’d been like…

Try saying it when you have a mortgage and two kids.
The Case for Creativity
Why some painters are able to paint masterpieces, is because they were able to progress from focusing on skill training to focusing on efficiency training, and then unlocking the level where they just focus on doing things (painting). Same is true for master musicians, martial artists, and any other highly demanding practice. The difference with a painter for example, and a data scientist, is that instead of having to learn how to hold the brush, and learning about different kind of brushes just once (skill) and then focusing on mastering it (efficiency), we data scientists have to learn about new kinds of brushes every single day. That’s part of the aspect of the game being rigged against the data scientist. As if that was not enough, we have to learn about meta-brushes and meta-meta-meta-meta-brushes. For most data scientists, regardless of their level, the skill aspect always takes a significant portion of their time. Either it’s learning about some new technology, or then something else. In terms of efficiency, very few people are actually efficient (even though they think they are). This means that creativity is not properly unlocked, there might be glimpses of it, but it does not have room to fully materialize. Instead, the data scientist uses their time with things like:
> Creating various specifications
> Data collection
> Cleaning up messy datasets
> Transforming features
> Looking for the most suitable model
> Looking for optimal model parameters
Needless to say, much of this could be (and will be) mostly, and in some parts fully automated in the not-so-distance future. For those data scientists, that have by then unlocked creativity, they will avoid the faith of becoming just more cogs in a giant machine. They become the planners and operators of the machine, as opposed to builders and janitors. This result is obvious and the causes are there to suggest it; most of the work most of the data scientist do, have to do with things that are not creative and are therefore cog-like. Next time when you do something, ask yourself how big portion of it could be replaced by a sufficiently capable machine. While it may seem very impressive now, knowing how to use a tool, or being good at a programming language, or anything of mechanical nature like that, is actually not impressive at all. Soon it will be roughly as impressive as we think conveyor belt work is today.
The only thing that is truly impressive, is human ingenuity. Creativity, as much as the word has been diluted by its use in the marketing context, in this case, is the essence of human ingenuity. This is what you should thrive towards. When you are a beginner, you don’t think about it, just focus on developing skill. When you are no longer beginner, you can focus slightly less on skill and more on efficiency. If you fail to make this distinction and do not make a conscious effort in reducing your skill training at the expense of efficiency improvements, it is like the car which makes a lot of sounds but does not do well in the race. At some point, you get into a kind of comfort zone where you feel like you can get a lot of things done and you feel like you can learn anything new quite ok, that is all skill development and is the lowest level on the three steps to mastery. It is a trap where most people become complacent with their paychecks and regular praise for meeting various targets and goals. If you can break free from this disillusioned state, and understand it only as a means to start focusing on efficiency instead, something beautiful happens. We can refer to that state as Man-Machine Symbiosis[5] with respect to the father of the idea (and the internet), JCR Licklider.
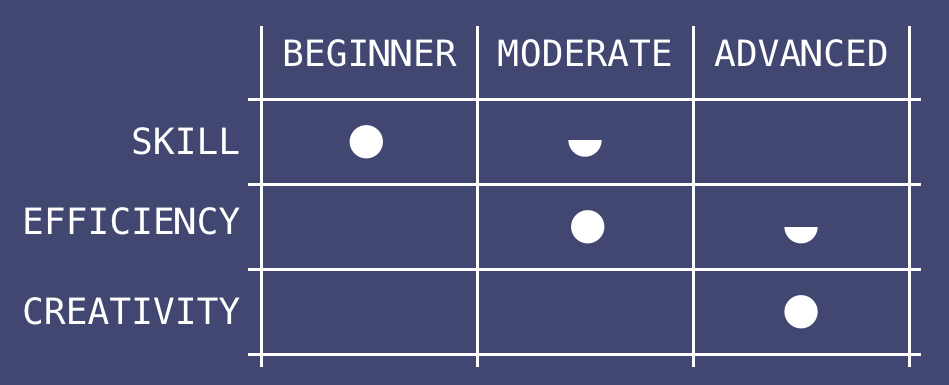
Our data scientists, she spent roughly 35% of her time somehow in association with data, not in the sense of the practice of extracting value out of it, but the practice of gathering it and refining it to the extent where extracting value would be possible. A task that already today is partially possible to outsource to AIs. To avoid this faith, as a global collective of data scientists, we should join together in fulfilling two essential goals:=
1. Improve the effectiveness with which individuals and organizations access insights and reliable predictions for decision making.
2. To develop and popularize a discipline by which greater effectiveness can be systematically achieved by practitioners
These two are derived from the goals Lick(lider) and his team set upon themselves nearly 60 years ago working in DARPA under Larry Roberts. When it comes to data science, it seems that everyone is way too busy brewing or drinking kool-aid, to feel the sense of responsibility of looking as far ahead as these great scientists did. Everything we do today in the digital world is to some extent thanks to them. With this in mind, we shall ask ourselves the question “what kind of legacy will I leave behind for those that come decades after?”.
The Last Third
With the remaining 1/3 of her time, she did something that other people can’t even imagine. It’s like being an alchemist of a sort. That’s one way of looking at it, with the difference that she could actually take something of no seeming value, and turn it into gold (money). Some of the work she did, while not a masterpiece that people will recognize or remember, was truly awe-inspiring, and those who could understand it, in some cases thought it was almost like magic. She got to be part of a global tribe of nerds, at a time when (finally) it had become desirable to be one. Having born in the 70s, as I wanted to be a fireman, the kids of the future no doubt will want to be data nerds. As great as this sounds, it begs the question “who paid the bills, who did she do this for?”. Like so many others like her, she did it for big banks that make most of their profits from those who can’t keep up with their payments, big advertisers who exploit the fears and desires of the so-called “consumers”, and government agencies that spy on their own people.
To make this last third truly meaningful, she would have had to leave her corporate slave masters and dedicate herself to solving really hard problems. Such as those outlined in the Copenhagen Consensus [6]. It’s one thing to do well in a Kaggle competition to beef up your resume and increase your odds in the job-market, and another to help 3 billion people in extreme poverty.
But we should not just stop at making 1/3 meaningful, but should thrive to make the entire journey meaningful. It has to start from the way we learn things first, how we are educated, how technology solutions allow us to learn by experience, and how there is a general shift away from trying to be clever calculators, to a genuine emphasis on human ingenuity. The data scientist career path needs to focus more on things that only human can do still 20 years from now as opposed to things that already could be done by machine today. Employers need to be more appreciative of talent when they find it, and when they don’t find it, they have to actively seek out ways to cultivate it.
Technology developers have a very important role to play in all of this; it needs to be realized that user manuals and meaningful support are at least as important as technological capabilities are. Better yet, solutions could be created so, that the need for documentation is avoided altogether. We’ve already come so far in terms of abstraction for the sake of capabilities (often at the expense of the user), that it is time for the focus to shift to abstracting on the terms of the user. The user experience of data science tools can be greatly improved with simple process automation, by emphasizing the needs of users at varying levels of capacity, and a commitment to designing for user interactions (as opposed to tool developers’ opinions). Once this happens, it is possible for data scientists to rapidly progress from skill development to efficiency development, and towards unlocking acquired creativity. For that is the essence of data science; man and machine functioning in symbiosis, so that the man can solve the world’s problems.
References
[1] https://www.quora.com/How-many-people-are-born-die-every-day-in-the-world-What-is-birth-to-death-ratio-in-the-world#!n=12
[2] http://gnosis.pm
[3] https://predictiontoken.github.io
[4] https://www.youtube.com/watch?v=yJDv-zdhzMY
[5] http://worrydream.com/refs/Licklider%20-%20Man-Computer%20Symbiosis.pdf
[6] http://www.copenhagenconsensus.com
READ MORE ARTICLES LIKES THIS